


Follow @solverworld Tweet this
Deep Neural Networks (DNNs) always leave me with a vague uneasy feeling in my stomach. They seem to work well at image recognition tasks, yet we cannot really explain how they work. How does the computer know that image is a fish, or a piano, or whatever? Neural networks were originally modeled after how biological neurons were thought to work, although they quickly became a research area of their own without regard to biological operation.
Well, it turns out that DNNs don’t work at all like human brains. A paper by Nguyen, et al 1 explores how easy it is to create images that look like nothing (white noise essentially) to the human brain, and yet are categorized with 99%+ certainty as a cheetah, peacock, etc. by DNNs that perform at human levels on standard image classification libraries. Here a small sample of images from their paper:
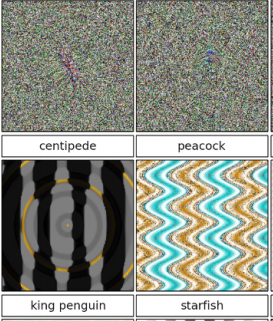 The researchers created the false images through an evolutionary algorithm that seeks to modify existing images through mutation and combination in order to improve on a goal, in this case to find images that would score highly with a DNN classifier (“fooling images”). They used a couple of methods, both of which worked. The direct method, illustrated in the top two images, works by direct manipulation of the pixels in an image file. The indirect method, illustrated in the bottom two images, works by using a series of formulas to generate the pixels; the formulas were then evolved. The idea was to create images that looked more like images and less like random noise. In both cases, the researchers found it easy to come up with images that fooled the DNN.
The researchers created the false images through an evolutionary algorithm that seeks to modify existing images through mutation and combination in order to improve on a goal, in this case to find images that would score highly with a DNN classifier (“fooling images”). They used a couple of methods, both of which worked. The direct method, illustrated in the top two images, works by direct manipulation of the pixels in an image file. The indirect method, illustrated in the bottom two images, works by using a series of formulas to generate the pixels; the formulas were then evolved. The idea was to create images that looked more like images and less like random noise. In both cases, the researchers found it easy to come up with images that fooled the DNN.
Their results also seemed robust. They performed various trials with random starting points, they even added their fooling images to the training sets, so as to warn the DNN that these were incorrect. Even after doing that, they were still able to find other fooling images that were misclassified by the new “improved” DNN. They even repeated this process as many as 15 times, all to no avail. The DNNs were still easily fooled.
As the authors point out, this ability of DNNs to be fooled has some serious implications for safety and security, for example in the area of self-driving cars. For real world results, see the Self-driving car hack.
There is something going on here that we do not fully understand. Researchers are starting to look into what features a DNN is really considering – which may help us to improve or alter the game for image recognition. Until then, pay attention to that pit in your stomach.
Notes:
- A. Nguyen, J Yosinkski, and J. Clune, Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images, Computer Vision and Pattern Recognition (CVPR ’15), IEEE, 2015 ↩